
はじめに
産業用ロボットの知能化が、現場の省力化と品質向上の鍵を握る時代が間近に迫っています。
特に「Vision Language Model(VLM:視覚言語モデル)」は、従来の画像認識AIとは次元が異なる可能性を秘めています。カメラで見た物体を「言語で理解」し、座標を特定したり、動作を計画したりできる。これが実用化できれば、ロボットの導入ハードルは劇的に下がります。
今回、私たちは中国Tencentが2026年4月に公開した HY-Embodied-0.5 というロボット向けVLMを、自社の検証環境(NVIDIA RTX 5070 Ti)で実際に動かし、産業現場での使い勝手を評価しました。
公開当初から「Gemini 3.0 Pro級」の性能を謳う発表があり、期待と懐疑の両方を抱えながらテストを開始しました。
検証対象:HY-Embodied-0.5とは
モデルの概要
| 項目 | 内容 |
|---|---|
| 開発元 | Tencent Robotics X × HY Vision Team |
| アーキテクチャ | Mixture-of-Transformers(MoT) |
| 公開モデル | MoT-2B(活性パラメータ約22億) |
| 未公開モデル | 32B(論文上のみ存在) |
| 特徴 | 空間推論・物体位置特定・動作計画を専門とするVLM |
Tencentの発表では、22のベンチマークで16項目で同サイズ帯の最先端モデルを上回り、32BモデルはGemini 3.0 Proに匹敵する性能と謳われています。
ただし、現時点で一般公開されているのは2Bモデルのみ。32Bモデルは論文上の存在に留まっています。
我々が期待した機能
- カメラ画像から複数物体の検出
- 正規化座標(0~1000)でのバウンディングボックス出力
- 物体の中心点(CENTER)の特定
- 言語による指示(「ボールを探して」「カゴに入れる軌跡を予測して」)への対応
検証環境と実装
ハードウェア
- GPU: NVIDIA GeForce RTX 5070 Ti(VRAM 16GB)
- CPU: Intel Core i9
- メモリ: 128GB
ソフトウェア構成
- Docker: nvidia/cuda:12.8.0 ベースイメージ
- Python: 3.12
- PyTorch: 2.8.0(CUDA 12.8対応)
- Transformers: Hugging Face公式の特定コミット版
- Flash Attention 2: 有効化
Web UIの構築
社内検証用に、FlaskベースのWebインターフェースを構築しました。
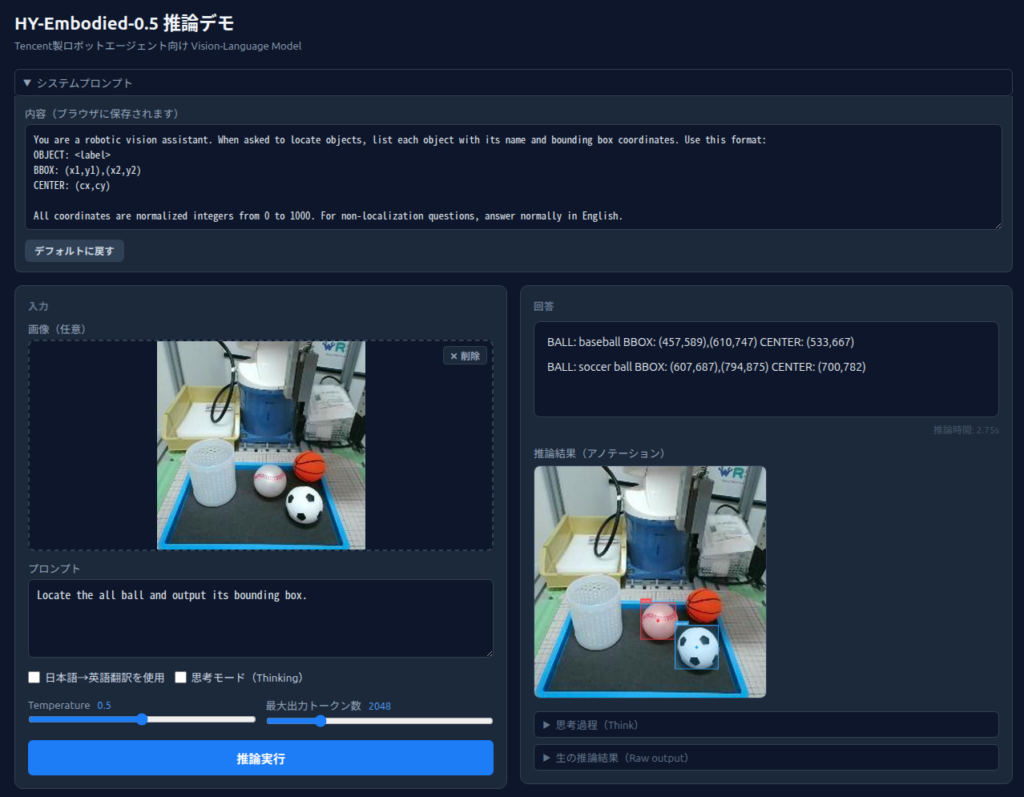
主な機能:
- 画像アップロード+プロンプト入力
- ストリーミング推論:生の推論結果をリアルタイムに表示し、完了後に折りたたむ
- 日本語→英語翻訳(GoogleTranslator経由)
- Thinkingモード(推論過程の表示)ON/OFF
- 推論履歴の保存と再実行
- バウンディングボックス・中心点の自動描画
画像は長辺1000pxにアスペクト比維持でリサイズし、そこに検出結果をオーバーレイ描画する仕組みとしました。
検証内容と結果
テスト1:基本的な物体検出
プロンプト: Locate the all ball and output its bounding box.
Thinkingモード OFF の場合
- 推論時間: 約1.9~3.4秒
- 結果: 3つのボール(baseball, basketball, soccer ball)を正しく検出
- 座標精度: おおむね正確。ただしモデルが出力する形式が毎回微妙に異なる
モデルの出力例:
OBJECT: Baseball
BBOX: (457,592),(617,748)
CENTER: (537,670)Thinkingモード ON の場合
- 推論時間: 約5.6~13秒(Flash Attention有効化後)
- 結果: 同様に検出可能だが、内部思考が長い
- 課題:
<think>タグ内で「本当にこれで合ってるか?」と自己確認を繰り返し、トークン数が増大
テスト2:構造化出力の検証
Tencentの公式READMEでは、座標表現として以下を謳っています:
<box>[xmin, ymin, xmax, ymax]</box><point>(x, y)</point>
しかし、実際のモデルはこれらのタグを一切使用しませんでした。
代わりに、テキストベースの独自形式(OBJECT:, BBOX:, CENTER:)で出力するため、パース処理に苦労しました。システムプロンプトでJSON形式を指示した場合は、モデルが困惑し、98秒間「plastic container」を無限ループするハルシネーションが発生しました。
結論:この2Bモデルは構造化出力(JSON/XML/特殊タグ)に向いていません。
テスト3:軌跡予測(物理推論)
プロンプト:
Given the soccer ball's current position at (707, 780),
predict the trajectory as it falls into the basket at (500, 600).- 推論時間: 27.4秒
- 結果: 3点の直線補間を提示((700,770) → (600,680) → (500,600))
- 課題:
- 指定座標(707,780)を勝手に丸めて(700,770)と出力
- 中間点の計算も正確ではなく、物理法則(放物線など)は考慮されていない
- 実用レベルの軌跡予測には程遠い
テスト4:座標形式の柔軟性
モデルは以下のような多様な形式を出力します:
# パターンA
OBJECT: baseball, BBOX: (456,586),(615,743)
# パターンB
BALL: baseball, BBOX: (459,587),(614,747)
# パターンC
The baseball ball: (456,592),(614,746)
# パターンD(座標だけ)
(454,588),(618,753)毎回形式が異なるため、堅牢なパース処理が必要です。産業用システムで使うには、この「出力の揺らぎ」が大きな障害となります。
我々が評価した「良い点」と「課題」
良かった点
- 軽量モデルながら物体検出は機能する
- 2Bパラメータで、画像から複数物体の位置を特定できる
- GPUメモリ16GBあれば快適に動作
- 思考過程の可視化が可能
- Thinkingモードで「なぜその座標か」の推論過程を確認できる
- デバッグや性能向上に役立つ
- Flash Attention 2で高速化
- 有効化前:Thinkingモードで18.9秒
- 有効化後:13.0秒(約31%短縮)
課題点(産業用として重要)
- 出力形式が不安定
- 構造化出力(JSON/XML)が苦手
- 毎回異なるテキスト形式で座標を返す
- 数値精度に問題
- 座標を勝手に丸めたり、コメントを出力に混ぜたりする
- ロボット制御に必要なミリ単位の精度は出ない
- 推論時間のばらつき
- Thinkingモードでは5~30秒と変動が大きい
- リアルタイム制御には不向き
- 論文と公開モデルのギャップ
- 「32BでGemini級」と謳われているが、公開されているのは2Bのみ
- 2Bの性能は「研究用デモ」レベルで、実用化には距離がある
産業用ロボットへの応用可能性
現時点で使える場面
- 研究・教育用デモ
- 概念実証(PoC)の初期段階
- 人間が最終確認する「支援的視覚認識」
現時点では使えない場面
- リアルタイムピッキングロボットの制御(推論が遅く、精度不足)
- 無人化された自動検査(出力形式が不安定でシステム連携が困難)
- 精密部品の位置特定(座標の丸め誤差が許容できない)
我々の見解
HY-Embodied-0.5は「産業用ロボットの脳」としては、現時点では未完成です。
ただし、Tencentのような巨大企業がこの分野に本格参入していること自体は重要なシグナルです。今後、32Bモデルが公開されたり、推論速度が最適化されたりすれば、状況は大きく変わる可能性があります。
重要なのは「技術トレンドを見逃さないこと」です。VLMによるロボット制御は、2~3年以内に実用レベルに到達する可能性が高いと考えます。
今後の展望と我々の取り組み
株式会社スリーアップ・テクノロジーは、製造現場のデータ取得とAI活用に9年以上従事してきました。
今回の検証で分かったのは、「現場のデータ」があってこそ、AIは真価を発挥するということです。VLMがどんなに進化しても、高品質な画像データと正確な位置情報を収集する仕組みがなければ意味がありません。
我々は以下の取り組みを強化していきます:
- 現場データの蓄積
- 産業用カメラとセンサーからの高品質データ取得基盤の構築
- ロボットの「目」として使えるデータセットの整備
- VLM技術の継続的モニタリング
- 今回のHY-Embodiedのように、新たなモデルが出たら即座に検証
- 実用レベルに達したモデルが出たら、お客様の現場に迅速に導入
- ハイブリッドアプローチの推進
- VLMだけに依存せず、従来の画像処理(OpenCV等)や物理シミュレータと組み合わせた堅牢なシステム設計
まとめ
Tencent HY-Embodied-0.5は「未来のロボットAI」の姿を垣間見せてくれる、興味深いモデルでした。ただし、現時点の2Bモデルは産業用として使える段階ではありません。
論文の主張ほどの性能はないものの、中国のテックジャイアントがこの分野に本腰を入れていることは事実です。産業用ロボットの知能化は、確実に近づいています。
製造現場の「データ基盤」を整え、最新技術を冷静に検証しながら、実用化の瞬間に備える──それが私たちスリーアップ・テクノロジーの役割だと考えます。
引き続き、産業用IoT・AIの最前線を発信していきます。
関連キーワード: VLM, Vision Language Model, 産業用ロボット, Tencent, HY-Embodied, 物体検出, AI, IoT, 製造業, ピッキングロボット
株式会社 スリーアップ・テクノロジー
- 産業用IoT・AI装置の開発・設置
- 28年以上の現場経験、50設備以上のAI/IoT化実績
- お問い合わせはこちら